In the early ages of software development, the waterfall model meant that code was tested and packaged over weeks and months. Products were deployed to users after being vigorously tested by QA teams. Branches would be created to ensure that new product development wouldn’t interfere with a release, and code freezes ensured only crucial bug fixes would enter the branch.
But the emergence of continuous integration/continuous deployment (CI/CD) changed all that. Though some of the process outlined above continues, these steps are expected to happen on the order of days or hours. Code can be changed and deployed to users multiple times a day. As a result, the time given to testing code is shorter, and there are more opportunities for bugs to enter software.
Why should I de-risk my code changes?
Code changes are more likely to introduce issues than code already in production. Avoiding these bugs saves developers headaches and wasted resources. By catching code issues early, organizations can help keep their product and data secure. And as development times have shrunk, so have the processes around checking and testing code.
Software developers are more responsible for shipping bug-free code and are on the hook for making fixes quickly any time of day (pager-duty anyone?). Although it’s not possible to push perfect code every time, developers can use automated tools to help them catch issues before they enter production.
Let’s take a look at two of those tools that help developers write safer code: static analysis and code coverage. Both of these can be inserted into the CI/CD pipeline or into the IDE giving tighter feedback loops to software developers to update code before it’s deployed.
What is static analysis?
Sloppy code is difficult to read and harder to maintain. It can contain bugs that are challenging for a reviewer to see and can cause headaches for developers if a bug is deployed. Similarly, developers aren’t always actively checking for security issues or compromised packages. Keeping outdated dependencies can cause sensitive data to be leaked to unfriendly parties. Addressing both sets of problems before code is deployed can help remove the risk of code changes.
Knowing if your code meets certain coding standards before you deploy can help ensure that a codebase is high-quality. Static analysis can be used as a tool to review code without running it. It is not limited to code standards and security issues, but can also find syntax errors and typing issues. After successfully running, static analysis will alert the developer of issues and their severity either in CI/CD or in a developer’s IDE.
Developers can depend on the wealth of knowledge and experience that comes with using a static analysis tool. Instead of having to know the most up-to-date practices, they can rely on rules outlined by teams of developers. Most importantly, using static analysis can save time and money for a team by providing actionable changes early in the development process. For more information about static analysis, check out this Snyk article.
What is code coverage?
Finding and fixing issues in code can take days of an engineer’s time. A bad deployment can cost thousands to millions of dollars before it can be fixed. Bugs can leave holes for malicious users to take advantage of vulnerable systems. So writing tests for code is one of the most important ways to preserve valuable resources.
When tests are run in CI/CD, information can be collected on which lines of code were run and which ones were not. This testing technique is called code coverage. It is often represented as a percentage of the total lines of code tested over the total number of lines in the codebase. A 100% coverage number represents all of the code that has been run when the test suite finishes. 0% means that no code was run.
Code coverage is invaluable to developers who are looking to ensure that the most important parts of their codebase are tested. We don’t recommend 100% code coverage, but knowing which lines aren’t run can help developers focus their test cases. Having a high coverage percentage helps to lower the risk of finding bugs in production. Programmers still need to write high-quality code and tests, which code coverage cannot check.
For more in-depth information about how code coverage works underneath the covers, check out Codecov’s e-book.
How do static analysis and code coverage work together?
Both static analysis and code coverage can be used to help detect bugs before a code change is pushed to production. Where they differ is in whether or not code is run. While static analysis doesn’t need to run code to produce results, code coverage is reliant on a developer’s knowledge imparted in a test suite to work. In this way, these tools can work in tandem giving developers a better chance of writing bugless code.
A developer writing code can benefit from the general developer population when running static analysis, while they benefit from themselves and their team’s specialized knowledge of the codebase when producing coverage results.
How to implement static analysis and code coverage in your codebases
Now that we understand a bit more about these two tools, let’s see how to implement them in your codebase. In this section, we’ll explain how to use Snyk and Codecov to deploy safer code.
Snyk for static analysis in the IDE
In the context of application security, static analysis helps developers to find security vulnerabilities by analyzing their code and without the need to execute it or have a running instance of an application. Static analysis is important because it can be embedded early on as part of the software development lifecycle without having to wait for security feedback after you build a working application or wait for it to build in a CI process or until it is deployed to production.
Some good indicators of developer-first security tooling are those that provide you with valuable information as quickly as possible, while you write code, and how better to do that than to integrate static security application testing within your IDE?
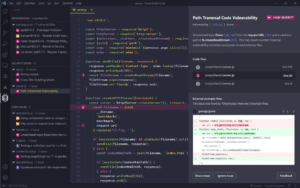
Snyk Code static analysis insights for a path traversal code vulnerability in VS Code IDE
By installing the Snyk Code extension, developers can find out about security vulnerabilities such as the Path Traversal vulnerability getting detected in the above codebase. Snyk Code not only shows you vulnerable code across multiple files and contexts but also provides you with guidance on how to fix a security issue, based on evidence seen in open-source code.
Codecov for code coverage in CI/CD
Codecov provides a way to get coverage information directly into a developer’s workflow. It works by collecting coverage reports created during a run of the test suite, aggregating them, and displaying coverage analytics on a pull/merge request and in the Codecov UI. This way, developers and reviewers can quickly get feedback about the test coverage of a code change.
The real power of Codecov is its ability to merge coverage reports together and display the coverage data in customizable ways. This allows engineering teams to decide on what parts of the codebase are important to them and how to ensure that testing standards are met. Using Codecov this way verifies that critical parts of the product have been tested before being deployed to production.
To get started with Codecov, you can follow our Quick Start guide. Here are also a few links you can use to get started with Codecov
– Documentation
– GitHub Tutorial
What else can I do to de-risk my code?
In this article, we’ve discussed the importance of de-risking code changes before they are deployed to production. We talked about how static analysis helps to find common anti-patterns and security issues and how code coverage can find holes in a testing suite. But what other tools can developers use to de-risk code?
Here are some other tools and reading that might be helpful
– What is mutation testing?
– Sentry’s application performance monitoring
– GraphQL Security Static Analysis
– Snyk’s online code checker