Code coverage is a useful tool to help developers find what lines of code are run. It works by keeping track of code that is run at execution time, either during a test run in a CI/CD or even in a production environment. This means that after a test suite is executed, code coverage reporters will output the lines of code that were not run as well as a percentage of lines of code run over the total number of lines in a codebase. For example, a test that only touches 6 out of 10 lines of code in a codebase will have a code coverage percentage of 60%.
In this article, we will discuss instances when reaching 100% code coverage is not worthwhile. Instead, a value around 80% is a much better target. We will also talk about how you can use Codecov to help focus your efforts on the parts of your codebase that matter.
Why 100% Code Coverage is not Always Ideal for Organizations
Getting a high code coverage percentage means that you are running all of your code at least once, which can raise trust in the breadth of your test suite. If you have 100% code coverage, your entire codebase successfully runs at least once. So why wouldn’t you aim for 100% coverage?
In a perfect world, 100% code coverage should be a requirement. It seems obvious that every single line of code should be covered by a test. More testing should lead to fewer bugs in production. But the reality is that getting to 100% is not often easy nor is it cheap.
-
Test Quality over Test Quantity
Many detractors of code coverage will say that relying solely on the percentage gives a false sense of security. What this means is that just because all of your code runs doesn’t mean that it’s going to give you the correct results. Take for instance the below code snippet.
def add(x, y): return x * yThe function
addis not returning the sum of two values, but instead the product. If we had a test written that does not actually check the return like belowdef test_add(): add(1, 2)we would see 100% code coverage, but the code would still have bugs. That means that organizations that prioritize high code coverage without investing in good tests are not going to gain any good benefits from tracking coverage. In fact, this is more likely to be harmful.
-
Engineering Time is Finite
This brings us to a second reason why 100% coverage can be detrimental. Engineering time is both costly and finite. Thus, it makes sense to prioritize our time with the most important and relevant work. Good engineers will take the time to understand how their code fits into the larger codebase and write tests to satisfy those conditions. But if someone doesn’t have or take the time to consider best practices, you could end up with a test like the above.
At some point, you might end up with a lot of tests like that above. But an organization might look at its code coverage percentage and be proud of the 100% coverage. However, as time goes on, the engineering team gets more and more bugs filed against code, and the management team wonders why this is happening if they are testing the entire codebase. A team will become disheartened and deem code coverage useless.
Let’s also consider that developers are not incentivized to write good tests for the last 10-20% of code that isn’t already covered. Sometimes, those last percentages are extremely difficult or cumbersome to write tests for. Whatever the case, in the time that a developer takes to get to 100%, they could have been pushing out a new feature.
-
Not All Code is Equal
A module that deals with billing or personal data is going to need to be much more important than an unused feature. Writing high-quality tests for crucial modules should take precedence over other parts of the codebase. And with finite engineering time, this sets up
What About 80% Code Coverage?
Hopefully, you’re convinced that 100% isn’t always a good idea. But is there another value that we can target that would make sense?
Although there is no perfect code coverage value, we can still make a stab at such a value. 2 years ago, Google posted a blog post on their best practices:
“We offer the general guidelines of 60% as “acceptable”, 75% as “commendable” and 90% as “exemplary.””
At Codecov, we see that a significant portion of our open source repositories centers around 80% coverage.
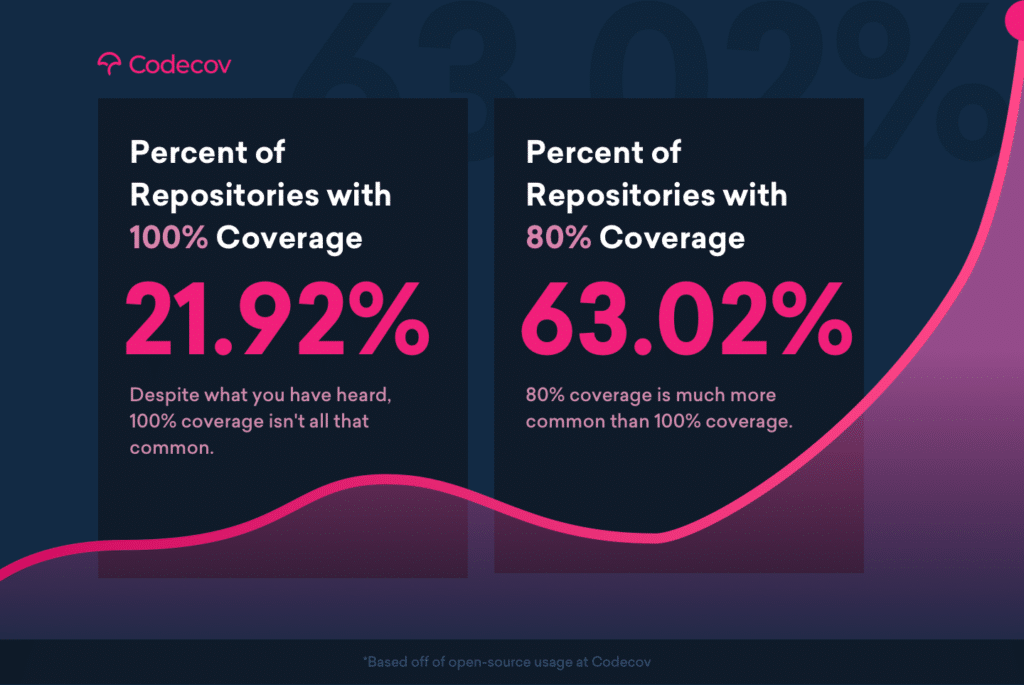
In fact, most repositories that use Codecov find that their code coverage values slide downwards when they are above 80% coverage.
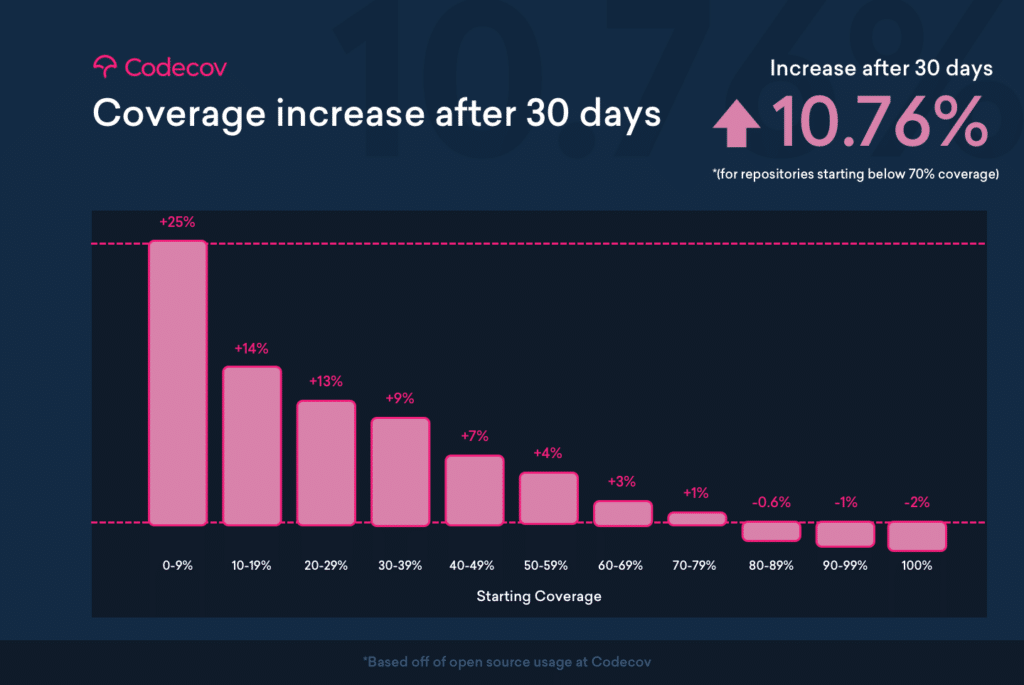
Although we can’t tell you what your code coverage value should be as every repository is different, we can strongly recommend aiming for somewhere between 75-85% coverage.
Using Codecov to increase code coverage
If your organization is new to code coverage, or you decide to create a culture of testing, we can provide a few helpful tips to getting to an 80% code coverage value.
-
Set project status target to
autoYou can use Codecov to automatically set up coverage gates on your entire codebase. By setting the target of your coverage to automatic, it will force PRs to increase the overall coverage of a codebase. You can insert the following snippet into a
codecov.ymlconfiguration file or learn more about project status checks.coverage: status: project: default: target: auto -
Set a high patch check
The Codecov patch check is used to measure the coverage of lines of code changed in a code change. Setting this to 100% ensures that all new code is fully covered with tests. You can do this in the
codecov.ymlconfiguration filecoverage: status: patch: default: target: 100% -
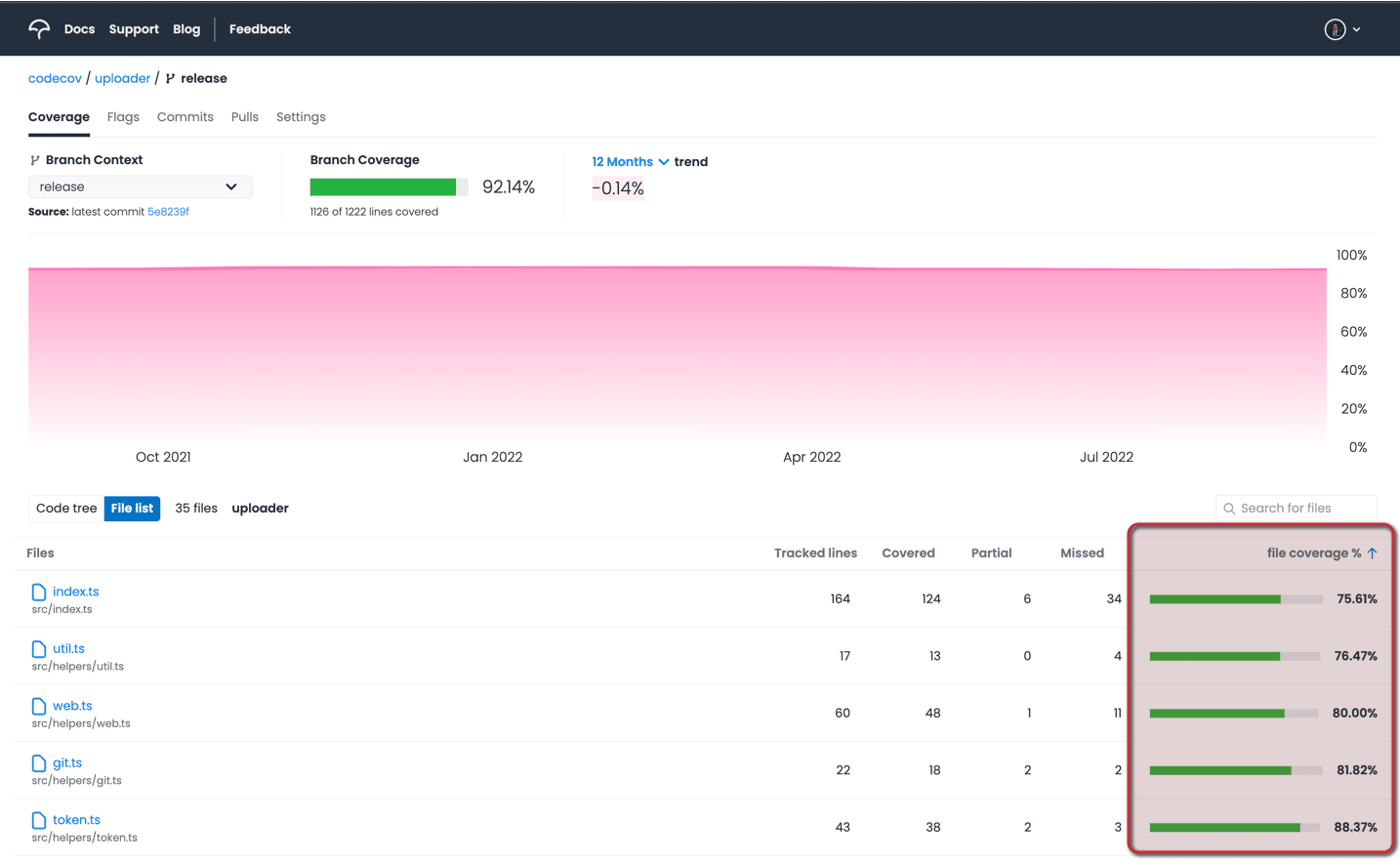
Use sort by file % feature
The fileviewer can be found in the dashboard of a repository. It clearly denotes files and directories that are not well covered with tests. Using this view can help direct a team to focus on pieces of the codebase that have the lowest test coverage.
-
Use Impact Analysis to identify critical code files
Impact Analysis marries runtime data with coverage information to figure out what are the most run lines of code in production. When you open a pull request that changes critical code, you will see designations in the Codecov PR comment that the file being changed is critical. This can help identify crucial pieces of your codebase.
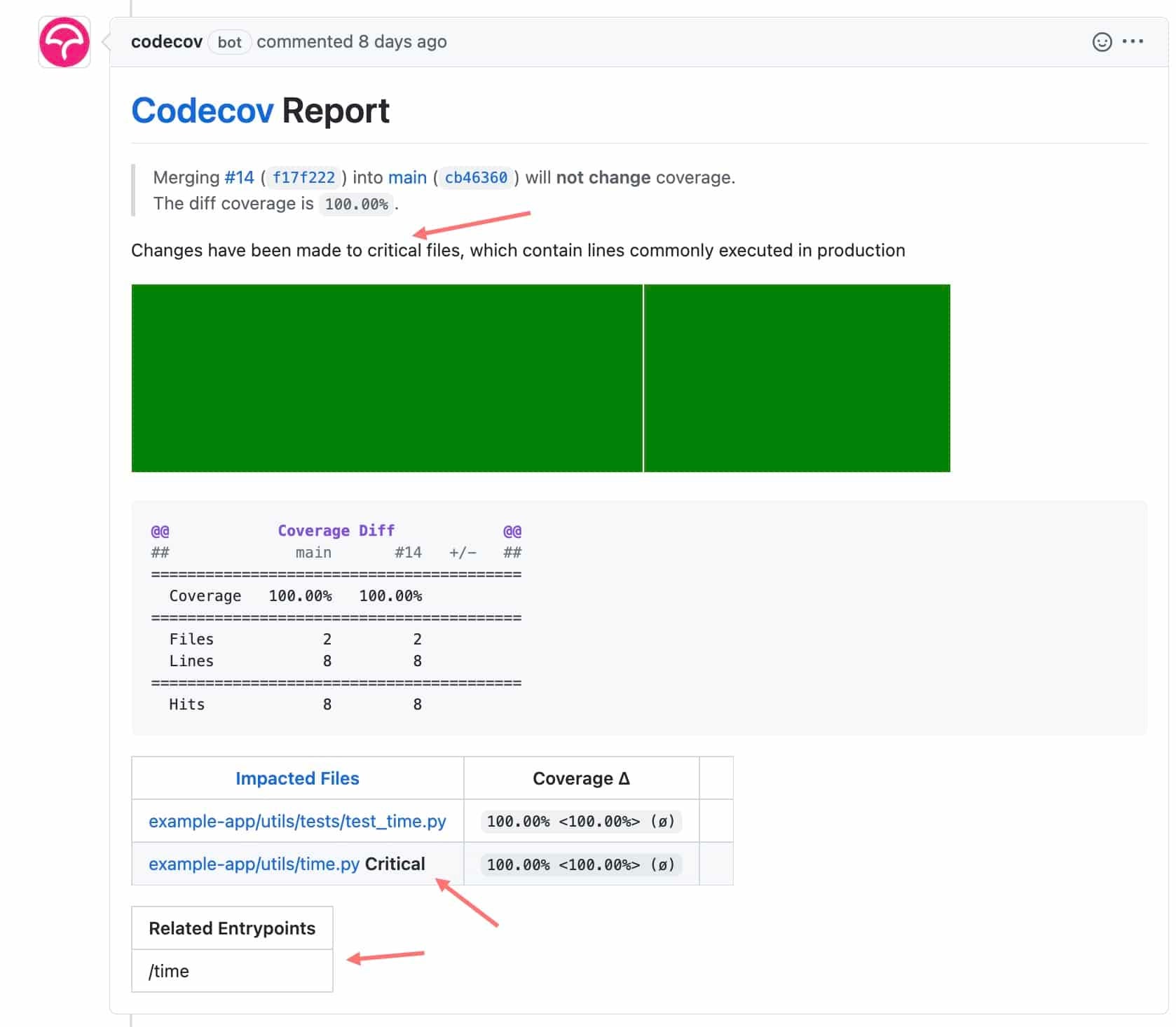
In this example, the code change is editing the file
example-app/utils/time.py. This file has been denotedCriticalbecause it has been run frequently on a production server.
Aiming for 100% code coverage can be detrimental and a huge drain on an engineering organization. Instead, it’s better to focus on high-quality tests that run through the most critical parts of your codebase. Writing good tests leads to having a strong testing culture which in turn leads to fewer bugs being deployed to production. So instead of setting a goal of 100%, aim for a coverage value (like 80%) that will actually lead to a better-tested codebase.