If you’ve written automated tests, you’ve probably encountered flaky tests. These tests produce inconsistent results, sometimes passing and sometimes failing without any changes having been made to the underlying code.
Flaky tests reduce confidence in your testing process and make it difficult to identify real issues in your code. Did this test fail because of a legitimate bug in the underlying code, or was it caused by something unrelated to the code? Investigating whether a failed test might be flaky wastes time and resources, making you a less productive developer.
Your best solution is to eliminate flaky tests. This blog shares eight strategies for identifying and eliminating flaky tests across different programming languages and frameworks. These aren’t just one-time fixes. Instead, incorporate these best practices into your typical workflow to ensure your test suite remains free of flaky tests.
Root Cause Analysis
Root cause analysis (RCA) investigates issues systematically until you identify, well, their root cause. For flaky tests, RCA helps uncover the real cause of a test’s failure, which is often not because of the underlying code but because of something less obvious, like a race condition, network-related issues, or time-dependent tests.
First, identify which tests in your test suite are passing inconsistently. You might have many, so start with tests that run most often, cover the most critical portion of your code, or have the highest failure rate. While you could do it yourself, Codecov’s test analytics feature will do this for you. Then, gather information about each test that can help identify the cause of the issue, such as logging, debugging, analyzing test execution orders, monitoring system resources, and stack traces. If possible, collect historical test results to see how the test failed over time. Use all of this information to look for the reason that the test fails.
For instance, consider the following Playwright test that checks if a user updating their profile works as expected:
import { test, expect } from '@playwright/test';
// Update the URL to point to the local instance of the application const LOCAL_APP_URL = process.env.LOCAL_APP_URL || 'http://localhost:3000/login';
test('user updates profile', async ({ page }) => {
// Login to the application
await page.goto(LOCAL_APP_URL);
await page.getByRole('textbox', { name: 'username' }).fill('testuser'); await page.getByRole('textbox', { name: 'password' }).fill('testpass'); await page.getByTestId('login-button').click();
// Navigate to profile page await page.getByTestId('profile-link').click();
// Update profile information
const newName = 'John Doe';
await page.getByRole('textbox', { name: 'name' }).fill(newName);
await page.getByTestId('save-button').click();
// Verify profile update
await page.reload();
const updatedName = await page.getByTestId('profile-name').textContent();
expect(updatedName).toBe(newName);
});
The test occasionally fails even though nothing related to the code has changed. If you run the test and collect logs, system resource reports, and stack traces, you’ll notice that memory usage increases significantly as the test executes. This hints at a memory leak in your code.
Upon closer inspection, you find that the database logic has retry logic to handle transient network failures when dealing with the database. You check to ensure the retry logic is causing no race conditions or memory leaks. It doesn’t look like there’s anything wrong there.
But hold on. Why is the retry logic executing so often? Transient errors are rare, especially when running integration tests in a pipeline. You analyze the database container for the integration. As you run the test, you notice that the database container is still starting and not ready for connections. That explains why memory usage is increasing: the database is still booting. The test fails because the retry logic needs to wait longer for the database to accept connections. You can use this information to implement a fix, such as ensuring your test suite runs only after verifying the database is ready for connections.
Environment Isolation
Inconsistent test environments can cause flaky tests. Isolating your test environment helps ensure consistency across test runs by reducing the number of external dependencies and improving their reproducibility.
You can use a few techniques to isolate your environment. The first is to design your tests to run with as few external dependencies as possible. For each dependency, examine if it’s essential for the test. If it’s not, try to eliminate it from the testing environment. Docker containers are an excellent solution for managing those dependencies you can’t eliminate when running tests. The containers are portable and run consistently across different platforms. You can quickly create containers when running tests and destroy them afterward, ensuring each test run starts with a clean slate.
For example, your application might use a database and send events to an event broker. All your tests need the database, but none need to test the event broker. In this case, you can eliminate the event broker when implementing tests and run your test database in a Docker container that gets recreated every time you run a new test.
Continuous Monitoring and Test Observability
You might notice flaky tests fail when run in a pipeline but pass when run locally. Observability practices like logging, metric collection, and screenshots of faulty tests can save you significant time when debugging flaky tests.
Ideally, this data should be stored close to the test results so that it’s easy to examine the cause of a test failure in a particular environment, such as in a pipeline.
For example, the JavaScript Playwright test below checks if a user can log into a web app successfully:
import { test, expect } from '@playwright/test';
// Update the URL to point to the local instance of the application const LOCAL_APP_URL = process.env.LOCAL_APP_URL || 'http://localhost:3000/login';
test('should log in successfully', async ({ page }) => { // Navigate to local login page await page.goto(LOCAL_APP_URL);
// Fill in username and password
await page.getByRole('textbox', { name: 'username' }).fill('testuser');
await page.getByRole('textbox', { name: 'password' }).fill('testpass');
// Click login button await page.getByTestId('login-button').click();
// Assert user is logged in by checking for welcome message
const welcomeMessage = page.getByTestId('welcome-message');
await expect(welcomeMessage).toBeVisible({ timeout: 10000 }); });
When you run the test locally, it works, but it always fails in the pipeline. The correct observability data can help you quickly uncover the cause of the test failure in a particular environment. In this case, you discover that the pipeline has an older version of Node.js installed, which causes parts of the application to fail. You can easily resolve the issue by updating the software to the correct version.
Retry Mechanisms
Tests can sometimes fail for nonfunctional reasons. Retrying these tests will save you from debugging every failure to determine whether the test failed for a functional or nonfunctional reason.
Consider the following Python test written using pytest:
import pytest
@pytest.mark.flaky(reruns=3, reruns_delay=2)
def test_retrieve_account():
account = retrieve_account('CLI453')
assert account != None
The method retrieves a client account from an external system, such as a database or external API. If the external system is temporarily unavailable, the test will fail, and you should consider retrying it.
Retry logic commonly retries tests three times before considering it a true failure, but you can adjust that number based on context.
You should also add a delay between each retry so that the transient issue can resolve itself. You can retry tests at fixed intervals, such as the two-second delay in the snippet above, use random time delays, or implement an exponential backoff delay, where the interval between each test increases with each retry.
If a test fails after it’s retried, there’s probably an issue in the code that needs to be investigated.
Mocking and Stubbing
As mentioned, removing external dependencies reduces the chances of flaky tests. Using mocks and stubs to mock peripheral services and dependencies lets you focus on testing a single method or portion of the code without worrying about other external dependencies or unrelated code. They’re often used for unit tests, but you can also use them in integration, functional, and performance tests to test a particular subset of features in an application and mock the rest.
Many programming languages have mocking libraries, such as Moq for .NET, unittest.mock for Python, and Sinon.JS and Mirage for JavaScript. The snippet below demonstrates mocking an `IUserRepository` in .NET using the Moq library:
using Moq;
public class UserServiceTests
{
[Test] public void GetUserNameById_UserExists_ReturnsUserName()
{
// Arrange
// Set up mock repository method
var mockRepository = new Mock();
mockRepository.Setup(repo => repo.GetUserById(1))
.Returns(new User { Id = 1, Name = "John Doe" });
var userService = new UserService(mockRepository.Object);
// Act
var result = userService.GetUserNameById(1);
// Assert
Assert.That(result, Is.EqualTo("John Doe")); } }
Rather than using a repository that reads and writes to an actual database where the connection can drop, this mocked repository runs faster and more reliably in memory.
Identify & Manage Inconsistent Test Data
Inconsistent data that varies between test runs can cause flaky tests. Managing test data so that it doesn’t vary between runs helps prevent this.
For starters, use consistent data for running tests. In other words, favor a static snapshot of data over dynamic data from a live environment that changes over time. (If you work with sensitive user data, remember to anonymize it thoroughly before using it for testing.) If you need more control over the test data or getting a snapshot of the actual data is tedious, you can also programmatically generate and use random data.
Also, be vigilant of less obvious dynamic data that can impact a test. For example, many systems get the current date from the server they’re running on when generating invoices or other performing logic that uses dates. However, if you use the server time when running tests, every test run will use a different date, which can result in flakiness. Implementing a function to retrieve the server date instead of using it directly in your code lets you mock the function in tests, ensuring consistent date values.
Idempotent Tests
Tests that impact a system’s global state and don’t revert those changes when finished can cause flakiness.
As far as possible, keep each test self-contained—or idempotent—so they don’t share any data or dependencies with other tests that can cause side effects. For example, before running each test, create a new in-memory data store for that particular test, populate it with data, and then run the test. Delete the temporary data store when the test finishes running since no other test will be using it. This isolation eliminates the risk of side effects affecting other tests.
When it’s impossible to run tests in complete isolation, undo all the changes made by the test in a teardown function. Also, make sure teardown functions cater to failed tests so that the test is idempotent regardless of whether it passes or fails.
The code snippet below shows how to undo changes after every test using the `tearDown` PHP function in Laravel:
use Illuminate\Support\Facades\Storage;
use Illuminate\Support\Facades\Config;
use Illuminate\Support\Facades\Cache;
use Illuminate\Foundation\Testing\RefreshDatabase;
use Tests\TestCase;
class ExampleTest extends TestCase
{
protected function tearDown(): void
{ // Example: Clear any created files
Storage::disk('local')->deleteDirectory('temp');
// Example: Reset any modified config values
Config::set('app.env', 'testing');
// Example: Clear cache
Cache::flush();
// Example: Reset mocked dependencies
$this->app->forgetInstance(SomeService::class);
// Always call the parent tearDown at the end
parent::tearDown();
}
/**
* A basic test example.
*
* @return void
*/
public function test_the_application_returns_a_successful_response()
{
$response = $this->get('/');
$response->assertStatus(200);
}
}
Reliable Locator Strategies
If you use locators in UI tests, avoid hard-coded selector paths. Rather, opt for rule-based or test-ID-based locators. Hard-coded selectors can be hard to read, especially if you have deeply nested elements. The smallest update to the HTML structure can also cause them to break.
For example, consider a simple change to the page structure like the one below:
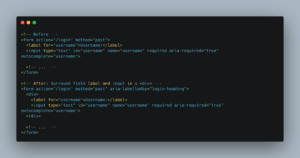
If you used the following XPath selector in a JavaScript Playwright test, it would break after the change above since the `input` is now wrapped in a div element:
const usernameInput = page.locator("/html/body/form/input[1]");
Using role-based and test-ID-based locators makes your tests more resilient. First, make sure you have the appropriate attributes in your HTML page:
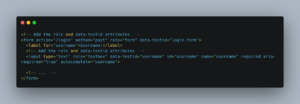
Then, use a role-based selector like the one below to select the username input element:
const usernameInput = page.getByRole('textbox', { name: 'username' });
You can also use the test-ID locator, such as the one below that selects the username input:
const usernameInput = page.getByTestId('username')
Neither the role-based nor ID-based locators reference the entire document structure, which makes them far more resilient to HTML changes.
Handle flaky tests with Codecov
Managing flaky tests is an important part of maintaining a robust and reliable test suite you can be confident in. The strategies and best practices in this article will help you identify and resolve flaky tests in your codebase. Remember to systematically work through your flaky tests, starting with the test that runs the most often or has the highest failure rate.
You can get a head start on addressing flaky tests by using Codecov’s new Test Analytics tool. It identifies failed and flaky tests within your CI, and tracks test suite stats over time so you know exactly where to start. Sign up for a free trial to see how Codecov can benefit your team.